- Published on
MobileVFX: Video Feature Extraction on Mobile and Embedded Devices
- Authors

- Name
- Cameron Cruz
Stanford CS231n 2019 Final Project [poster] [paper]
Abstract (exerpted from paper):
The increasing ubiquity of video-enabled mobile and IoT devices motivates a growing desire to deploy video-understanding models on the edge. While traditional methods use large 3D CNN architectures with prohibitively expensive compute requirements, recent research demonstrates that 2D CNN image classification networks can learn spatio-temporal features with the addition of Temporal Shift modules (TSM). However, while TSM is proven to be successful in 2D networks such as ResNet-50, this is still too computationally intensive to deploy on embedded devices. In this paper, we propose MobileNetV2 equipped with TSM as an extremely efficient architecture for video-understanding tasks. We also enhance the training process by utilizing knowledge distillation loss to enable this lightweight architecture to achieve near state-of-the-art performance. On the Jester dataset, where spatio-temporal feature learning is critical, our method achieves 4.1x higher throughput using 3.4x less FLOPS and 9.9x fewer parameters than TSM-equipped ResNet-50 with an accuracy that is only 1.5% below state-of-the-art. We also successfully deploy this architecture using the TFLite format to a mobile device (iOS) where it performs online inference.
Motivation
The goal my partner (Zen Simone) and I had with MobileVFX was to see if we could run video-based action recognition on a mobile device. The key here is being able to detect temporal in addition to spatial features. For example, the temporal sequence of video frames is important to distinguish "swiping right" from "swiping left".

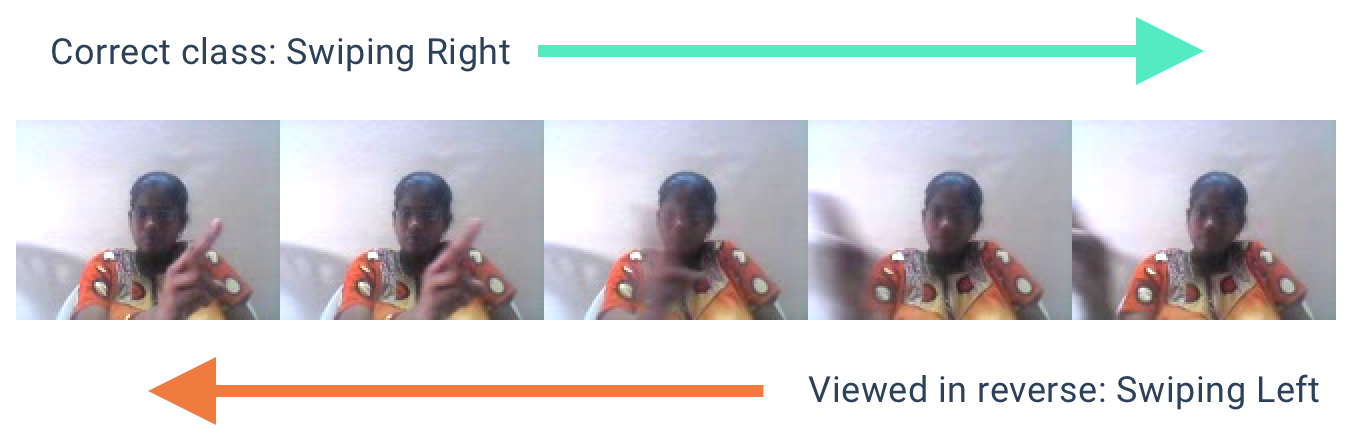

Approach
Video data is the big data of big data, and previous approaches used large 3D CNNs, hybrid 2D-3D CNN architectures, 2D CNN + RNN, etc. These were all enormously computationally expensive, and our efforts to modify and optimize these approaches were unsuccessful.
However, the MIT Han Lab published a paper that year introducing the idea of the temporal shift module (TSM).1 The idea behind TSM is that you can enable a 2D CNN to learn both spatial and temporal features without introducing any additional parameters.
Here's how TSM works: Imagine your input is 8 frames of video. On each frame, you run your 2D CNN backbone (MobileNet, for example) to extract features, except at different stages in the network, you shift values along the channel dimension forwards and backwards in time. For example, if you did this on the initial RGB input, you can imagine shifting all the red pixels forward to the next frame, and all the blue pixels backward to the previous frame. In this way, you're sharing features temporally, and so the same 2D CNN backbone is able to learn spatiotemporal features due to the shift.

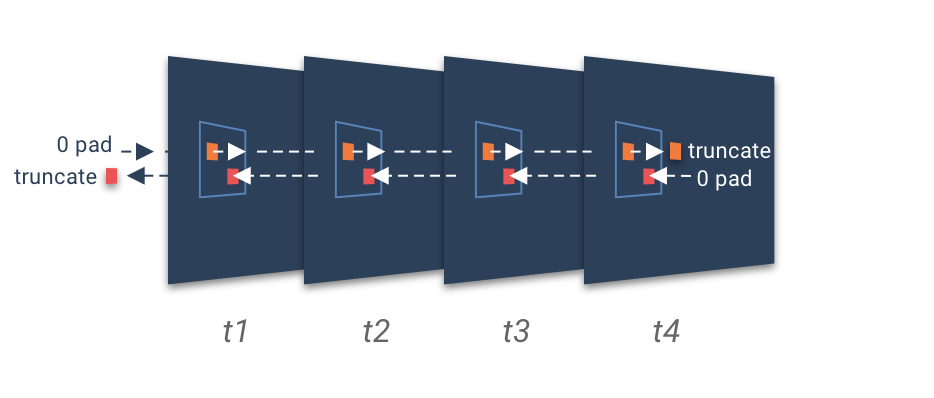
Note: You actually wouldn't do this on the initial input. Generally, you start from the top of the network, and can add more TSM modules progressively towards the bottom of the network. Depending on how deep the module is in the network, the intermediate feature volumes may have any number of channels. 1/8 to 1/2 of the channels (total for forward and backward combined) is sufficient, the important thing is that the same channels are shifted across all inputs.
The researchers at MIT Han Lab had published TSM with ResNets, and so we weren't sure how it would translate to MobileNet. We found that the accuracy wasn't nearly as good as current SOTA. To address this, we introduced knowledge distillation loss2 with a 3D version of Inception as the teacher model (pretrained weights were available online). Knowledge distillation improved the accuracy dramatically, resulting in performance near equal to that of SOTA models at the time.

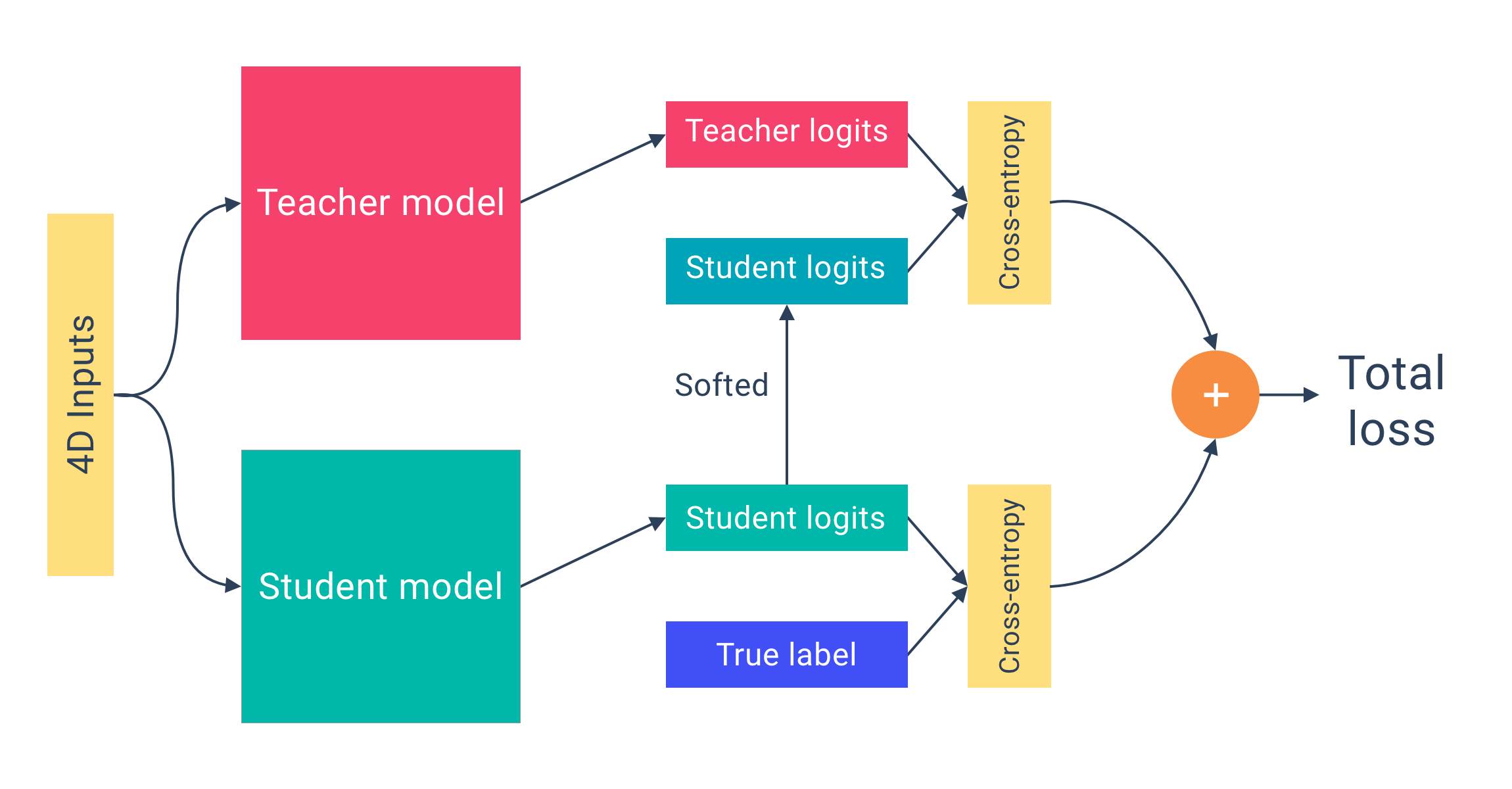
Results
The final result was a model that achieved near equal performance with a 4X higher throughput, 3.4X less FLOPS, and 10X fewer parameters compared to SOTA models at the time.
We also built a live iOS demo that could classify temporally sensitive gestures in entirely on-device, with an average inference time of 74ms or 13.4 fps.
At the end of the poster presentation day, we were awarded the Best Project Award for our work with MobileVFX.
For more details on our work (Literature Review, Datasets, Methods, Results/Analysis, etc.) please check out our final poster and full paper.